
自社の業務に特化した指示を出しても、生成AIが期待通りの回答をしてくれない。そんな悩みを抱えていませんか?汎用的なAIモデルでは、社内特有の専門用語やブランドのトーンを完全に理解するのは困難です。この課題を解決する技術が
「ファインチューニング」です。
ファインチューニングとは、既存の学習済みAIモデルに対し、自社独自のデータを追加で学習させることで、特定の目的に合わせてカスタマイズする手法です。 これにより、まるで自社の業務を熟知した専門家のように、的確な回答を生成するAIを育て上げることが可能になります。この記事では、ファインチューニングの基本的な仕組みから、混同されがちな
「RAG」との違い、具体的な導入手順、コスト、そして企業の成功事例までを網羅的に解説します。
専門的な知識がなくても、AIを自社の強力な戦力に変える方法は存在します。弊社
「AX CAMP」では、AI導入の企画から実装、社内への定着までを伴走支援するサービスを提供しており、ファインチューニングのような高度な活用についてもサポートしています。まずは本記事で、自社専用AIを構築するための第一歩を踏み出しましょう。

ChatGPT・RAG・AIエージェントなど、導入検討で迷いやすいAI用語を実務目線で整理。
生成AIのファインチューニングとは?
生成AIのファインチューニングとは、既存の学習済みAIモデルを、自社独自のデータセットで追加学習させ、特定のタスクに特化させる手法です。大規模なデータで基本的な能力を身につけた汎用モデルをベースに、専門知識や独自の文体を教え込むことで、自社専用のAIモデルを構築することを目的とします。
この技術の導入により、汎用モデルでは難しかった、業界特有の専門用語への対応や、企業文化に合わせたトーンでの文章作成などが可能になります。実際に、弁護士ドットコム株式会社が開発・提供する「Legal Brain」は、法律専門書籍や判例など信頼性の高いデータを追加学習させることで、法務リサーチ業務に特化しています。 一度ファインチューニングを行えば、簡単な指示(プロンプト)で精度の高い回答を得られるため、業務効率の大幅な向上が期待できるのです。
基本的な仕組みと目的
ファインチューニングの仕組みは、膨大なデータで事前に学習された「ベースモデル」の汎用的な知識の上に、特定のタスクに特化した少量のデータを追加で学習させるものです。 このプロセスを通じて、モデル内のパラメータ(重み)が微調整され、特定の分野や目的に最適化されます。
その主な目的は、以下の4点に集約できます。
- 特定タスクの精度向上
- 専門用語や文脈の学習
- ブランドトーンの統一
- キャラクターの一貫性維持
例えば、法律分野に特化したAIを開発するケースを考えてみましょう。過去の判例や法令といった専門データを追加学習させることで、契約書レビューの精度を高めたり、法律相談の初期対応を自動化したりできます。 このように、企業の特定のニーズに合わせてAIの性能を引き出すことが、ファインチューニングの基本的な目的と言えるでしょう。
ただし、専門的なシステムであってもAIが事実と異なる情報を生成するリスク(ハルシネーション)は存在します。 実際に、海外ではAIが生成した架空の判例を弁護士が裁判所に提出してしまった事例も報告されています。 そのため、生成された内容はあくまで参考情報として扱い、最終的な法的判断は必ず弁護士などの資格を有する専門家が行う必要があります。
転移学習との関係性
ファインチューニングは、「転移学習(Transfer Learning)」と呼ばれる機械学習の手法の一種です。転移学習とは、ある領域で学習したモデルの知識を、別の関連する領域のタスクに応用する技術全般を指します。
生成AIにおける転移学習では、まずインターネット上のテキストデータなどで汎用的な言語能力を持つ「事前学習済みモデル」を作成します。その際、第三者の著作物を利用する場合は、利用許諾の取得や著作権法上の適法性を検討する必要があります。その後、そのモデルをベースに、特定のタスクに関する少量のデータで追加学習を行います。この追加学習のプロセスこそが「ファインチューニング」なのです。転移学習という大きな枠組みの中に、モデル全体または一部のパラメータを新しいデータで微調整するファインチューニングが含まれると理解すると分かりやすいでしょう。(出典:スタンフォード大学 CS 230 チートシート)
プロンプトエンジニアリングとの違い
プロンプトエンジニアリングは、AIへの「指示の出し方」を工夫することで、望ましい出力を引き出す技術です。モデル自体に変更は加えず、入力(プロンプト)を最適化することに焦点を当てます。役割を与えたり、出力形式を指定したり、いくつかの例を示したりすることが含まれます。
一方で、ファインチューニングはAIモデルそのものを追加データで再学習させ、モデルの内部パラメータを更新するアプローチです。プロンプトエンジニアリングが「AIの上手な使い方」の技術だとしたら、ファインチューニングは「AIそのものを特定の目的に合わせて改造する」行為にあたります。
毎回長いコンテキストをプロンプトに含める必要がある複雑なタスクや、一貫したブランドトーンが求められる場合、プロンプトの工夫だけでは限界があります。このようなケースでは、ファインチューニングによってモデル自体に知識やスタイルを組み込む方が、より効率的かつ安定的にパフォーマンスを発揮できる可能性がありますが、その効果は環境やデータに依存します。
https://a-x.inc/blog/ai-hallucination
ファインチューニングとRAGの徹底比較
ファインチューニングと共によく比較される技術に「RAG(Retrieval-Augmented Generation)」があります。両者はAIの応答精度を高める目的は同じですが、そのアプローチは根本的に異なります。ファインチューニングがモデル自体を「再訓練」するのに対し、RAGは外部の知識源を「都度参照」して回答を生成する手法です。
どちらの手法を選択するかは、目的、コスト、そして求める応答の性質によって大きく変わってきます。それぞれの仕組みと特性を理解し、自社の課題に最適なアプローチを見極めることが重要です。
RAG(Retrieval-Augmented Generation)の仕組み
RAGは「検索拡張生成」と訳され、その名の通り「検索」と「生成」を組み合わせた技術です。RAGのシステムは、ユーザーから質問を受け取ると、まずその質問に関連する情報を社内文書やデータベースなどの外部知識ソースから検索します。
そして、検索して見つけた関連情報を、元の質問と一緒にAIモデルへのプロンプトに含めて渡します。AIモデルは、その提供された情報を「参考資料」として利用し、回答を生成する仕組みです。これにより、モデルが元々学習していない最新の情報や、社外秘のデータに基づいた回答が可能になります。
目的と得意なタスクの違い
ファインチューニングとRAGは、それぞれ得意な領域が異なります。ファインチューニングは、モデルに特定の「スタイル」や「振る舞い」、「暗黙知」を学習させるのに適しています。例えば、特定のキャラクターの口調を模倣させたり、複雑な専門用語のニュアンスを理解させたりする場合に有効です。
一方、RAGは、常に最新の情報や正確性が求められる事実に基づいた回答を生成するのに非常に強力な手法です。社内の最新規定に関する問い合わせ対応や、日々更新される製品情報に基づいたFAQチャットボットなどが典型的なユースケースとなります。結論として、知識の更新頻度が高いタスクにはRAG、モデルの根本的な能力やスタイルを変えたい場合はファインチューニングが向いています。
| 比較項目 | ファインチューニング | RAG (Retrieval-Augmented Generation) |
|---|---|---|
| アプローチ | モデル自体を追加データで再学習(知識の内在化) | 外部データベースを都度検索し、参照して回答(知識の外部化) |
| 得意なタスク | ・文体、トーンの統一 ・専門的な対話スタイルの学習 ・暗黙知の獲得 | ・最新情報に基づく回答 ・社内文書や規定の参照 ・事実確認(Fact-Checking) |
| 知識の更新 | 再学習が必要 | データベースの更新のみで対応可能 |
| ハルシネーション | 学習データに依存。抑制は可能だがリスクは残る。 | 参照元が明確なため、抑制しやすい。 |
コストと実装難易度の比較
一般的に初期コストと技術的なハードルはファインチューニングの方が高い傾向があります。対して、RAGはモデルそのものを再学習せずにそのまま利用できるため、モデル学習にかかるコストは抑えられがちですが、検索インフラやデータベース構築・運用には別途コストが発生します。
たとえば、社内文書などを検索可能にするためのデータベース(ベクトルデータベース)の構築と、継続的なデータ管理のコストが発生します。技術的な観点では、RAGの方が比較的少ない専門知識で実装しやすいと言えるでしょう。
ハルシネーション(幻覚)への耐性
ハルシネーションとは、AIが事実に基づかないもっともらしい情報を生成してしまう現象です。この問題に対する耐性では、一般的にRAGの方が優れています。この用語と課題については、野村総合研究所のナレッジ・インサイトでも解説されています。
RAGは、回答を生成する際に必ず外部の具体的な文書を参照するため、その情報源を明記させることが可能です。 例えば、社内の最新の経費精算ルールについて質問された場合、参照した規定文書名と該当ページを回答と同時に示せます。これにより、ユーザーは回答の根拠を自身で検証でき、AIが誤った情報を生成するリスクを大幅に低減できます。
一方、ファインチューニングされたモデルは、知識がモデル内部に統合されています。そのため、なぜその回答に至ったのかの根拠を明確に示すことが難しいという課題があります。
さらに、情報の鮮度も大きな課題です。仮に2025年時点のデータで業界知識を学習させた場合、2026年以降の新しい規制や市場動向を反映できず、古い情報に基づく回答を生成するリスクが残ります。 この「知識のカットオフ」問題は、ファインチューニングという手法が持つ構造的な限界です。
IBMの記事で解説されているように、モデルの知識を更新するには再学習が必要で、それには時間とコストがかかります(IBM Think)。このため、OpenAIのGPT-5.6(2026年7月時点)のような高性能なモデルでも、ファインチューニングだけではこの課題を完全には解決できません。したがって、常に最新かつ正確な情報源を参照できるRAGの仕組みが、ビジネス利用において極めて重要です。
ハイブリッドアプローチの可能性
ファインチューニングとRAGは排他的な関係ではなく、両者を組み合わせる「ハイブリッドアプローチ」も非常に有効です。このアプローチでは、まずファインチューニングによってモデルに業界特有の専門知識や対話スタイルを学習させ、基本的な応答性能を高めます。
その上で、RAGの仕組みを導入し、最新の社内データやリアルタイム情報を参照できるようにします。これにより、専門性と即時性を両立した、非常に高性能なAIシステムを構築できます。例えば、専門的な法律知識を持ちつつ(ファインチューニング)、最新の判例データを参照して回答する(RAG)といった高度な応用が考えられます。
https://a-x.inc/blog/ai-benefits
図解でわかる!ファインチューニングとRAGの使い分け
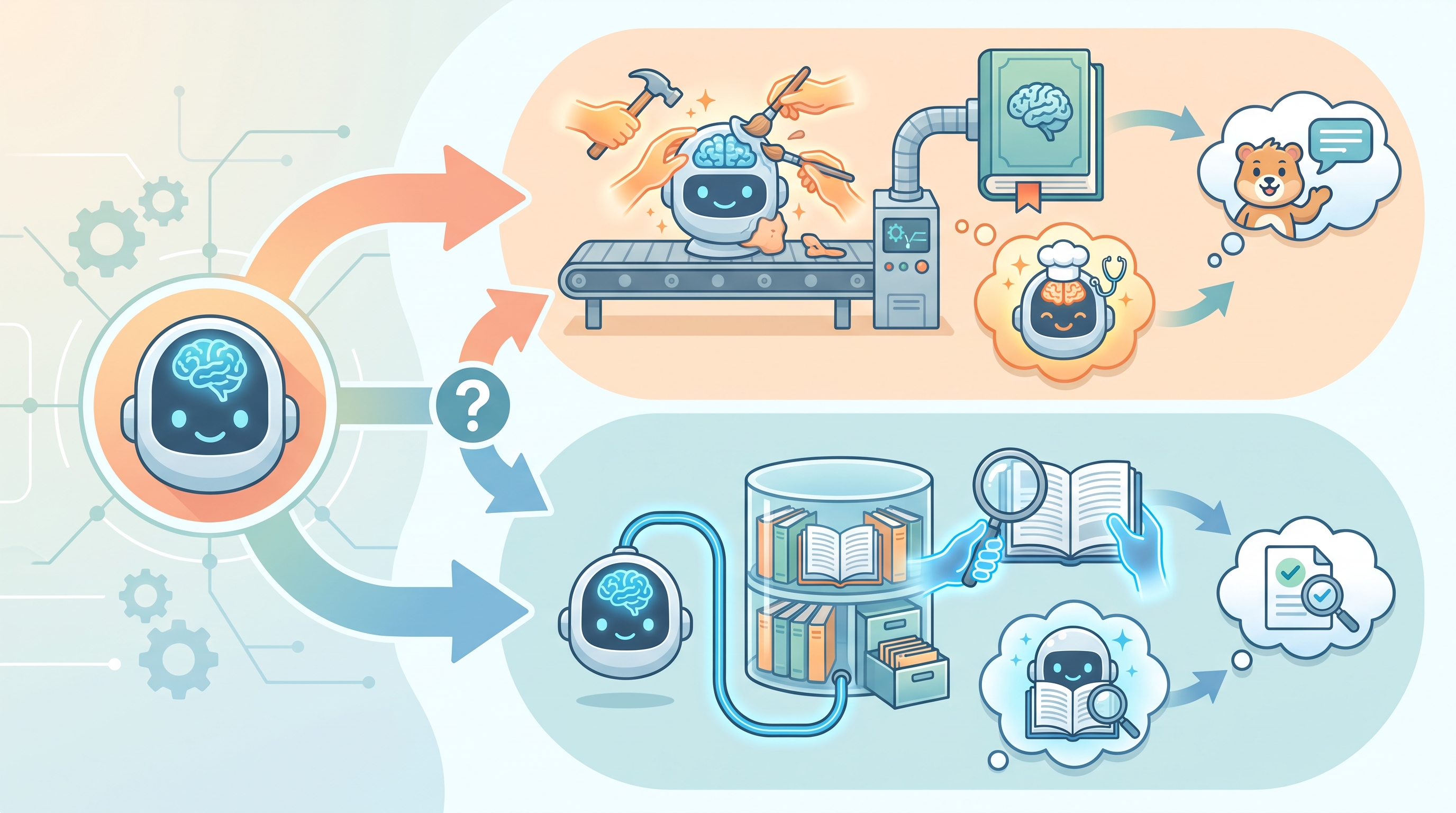
ファインチューニングとRAGのどちらを選ぶべきか。その判断は「AIに何をさせたいか」という目的によって明確に分かれます。モデルの振る舞いや応答スタイル自体を特定の方向に「教育」したいのか、あるいは外部の正確な情報に基づいて「回答」させたいのかを考えることが重要です。
それぞれの技術が適した場面を、具体的なユースケースで見ていきましょう。この使い分けは、GPT-5.6やGemini 3.5のような最新世代のAIモデルを利用する上でも基本となる考え方です。
- ファインチューニングが適しているケース
特定の文体や専門用語、企業のブランドイメージに沿った応答など、AIの「個性」や「話し方」を根本から変えたい場合に有効です。例えば、特定のキャラクターとして対話するAIアシスタントや、特定の思考様式を模倣する分析ツールを開発する際に選択されます。 - RAGが適しているケース
社内規定、マニュアル、最新の製品情報など、常に更新される正確なデータに基づいて回答させたい場合に最適です。回答の根拠が明確になるため、ハルシネーション(事実に基づかない情報の生成)を大幅に抑制できる点も大きな利点です。
つまり、AIの「能力・人格」を拡張するのがファインチューニング、AIの「知識」を外部から与えるのがRAGと理解すると、その使い分けがより分かりやすくなります。
生成AIにファインチューニングを行うメリット

ファインチューニングの最大のメリットは、汎用モデルを自社の特定のニーズに合わせて最適化し、業務における回答精度と効率を飛躍的に向上させられる点にあります。これにより、他社には真似のできない、独自の競争優位性をAI活用において確立できます。
社内に存在する膨大な知識やノウハウをAIに学習させることで、これまで属人化していた業務の標準化や、新たな価値創出のきっかけにも繋がるでしょう。具体的なメリットを4つの側面から見ていきます。
特定タスクにおける回答精度の向上
ファインチューニングによって、AIモデルは特定の業界や業務領域に特化した知識を深く学習します。これにより、一般的なモデルでは曖昧な回答しか得られなかった専門的な質問に対し、専門知識を補助する高精度の回答を生成する可能性があります。
例えば、製造業であれば特定の部品に関する技術的な問い合わせ、金融業界であれば複雑な金融商品に関する説明など、専門性が求められる場面でその真価を発揮します。ただし、生成される回答は参考情報であり、最終的な判断は必ずその分野の専門家が行うべきです。この点を留意することで、顧客満足度の向上や、社内エキスパートの業務負荷軽減に繋げられます。
自社独自の専門用語や文脈の学習
どの企業にも、社内でのみ通用する独自の専門用語、略語、あるいは製品コードなどが存在するものです。汎用的なAIモデルはこれらの固有名詞を理解できず、的外れな回答を返すことが少なくありません。
ファインチューニングを行えば、こうした自社独自の言語文化や業務文脈をAIに学習させることが可能です。その結果、社内文書の検索、議事録の要約、日報の作成といった内部業務の効率化が大きく進みます。社員はAIに対して、普段使っている言葉で自然に指示を出すことができるようになるのです。
ブランドトーンやキャラクターの一貫性維持
顧客向けのコミュニケーションにおいて、ブランドイメージに沿った一貫したトーン&マナーを保つことは非常に重要です。ファインチューニングを活用すれば、企業のブランドガイドラインや過去の優れたマーケティングコピーをAIに学習させ、ブランドイメージに合致した文章を自動生成させることができます。
これにより、SNS投稿、メールマガジン、広告コピーなどの作成業務において、品質を維持しながら大幅な時間短縮が実現します。また、特定のキャラクターを設定したチャットボットなど、よりエンゲージメントの高い顧客体験を提供することも可能になるでしょう。
プロンプトの簡略化による利用効率アップ
ファインチューニングされていない汎用モデルに複雑なタスクを依頼する場合、毎回長文のプロンプトで詳細な背景情報や前提条件、出力形式などを指示する必要があります。これは利用者にとって大きな負担となり、AI活用の定着を妨げる一因にもなり得ます。
ファインチューニングによってモデル自体がタスクの文脈を理解しているため、利用者は非常に短い、簡潔なプロンプトでAIを操作できるようになります。例えば、「先月のA製品に関する週次レポートを作成して」といった短い指示だけで、事前に学習させたフォーマット通りのレポートが生成されるようになります。この利便性が、全社的なAIの利用促進と生産性向上に繋がります。
https://a-x.inc/blog/ai-issues
生成AIファインチューニングのデメリットと注意点
ファインチューニングは強力な手法である一方、導入にはいくつかのデメリットや注意すべき点が存在します。主な課題は「高品質なデータの準備コスト」と「継続的な運用コスト」の2つに集約されます。これらの課題を理解し、十分な計画を立てずに進めてしまうと、期待した効果が得られないばかりか、予期せぬコストが発生する可能性があります。
成功のためには、メリットだけでなくデメリットにも目を向け、現実的な導入計画を策定することが不可欠です。ここでは、特に注意すべき4つのポイントを解説します。
高品質な学習データの準備コスト
ファインチューニングの成否は、学習させるデータの質と量に大きく依存します。モデルに特定の振る舞いを学習させるには、「指示(プロンプト)」と「理想的な出力」を対にした、高品質なデータセットが最低でも数十件、複雑なタスクでは数千件以上必要になるとされています。 重要なのは量よりも質であり、質の高いデータが少量あれば、大量の低品質なデータを上回る効果が期待できます。
このデータセットを作成する作業には、専門知識を持つ人材による多大な時間と費用がかかります。具体的には、データ1件ごとに最適な指示と回答を設計・検証するアノテーション作業が発生し、AIの性能を直接左右するため高い専門性が求められます。 さらに、個人情報を含むデータを扱う場合は、個人情報保護法に準拠した対応が必須です。個人を特定できる情報を除去する匿名化処理や、データ利用に関する本人からの適切な同意取得など、法務・セキュリティ面の追加コストも考慮しなくてはなりません。
もしデータに誤りや偏りがあれば、AIはそれを忠実に学習してしまいます。その結果、事実と異なる情報を生成したり、不適切な応答を返したりするなど、ファインチューニング前より性能が低下するリスクさえあります。 このような「過学習」と呼ばれる現象を避けるためにも、慎重なデータ準備が極めて重要です。
(出典:ファインチューニングのデータとコスト)
モデルの学習と維持にかかる計算コスト
モデルの学習プロセスには、高性能なGPU(Graphics Processing Unit)などの計算リソースが不可欠です。実際に、NVIDIAによる解説(2026年1月)でも示されているように、ファインチューニングを効率的に行うには、大量の計算を高速に処理できる能力が求められます。
自社で高性能なサーバーを保有していない場合は、クラウドサービスを利用するのが一般的です。これには学習時間や処理したデータ量に応じた利用料金が発生し、試行回数が増えるほどコストは増加します。
また、一度ファインチューニングしたモデルを使い続けるだけでは、技術の進化に取り残される可能性があります。例えば、OpenAIが「GPT-5.5」からより高性能な「GPT-5.6」へアップデートした場合、その恩恵を受けるためには再度ファインチューニングが必要になることがあります。
このように、初期の学習コストだけでなく、モデルを最新の状態に保つための継続的な維持コストも考慮に入れる必要があります。(出典:Introducing vision to the Fine-Tuning API)
(出典:RTX AI Garage – Fine-tuning)
過学習(Overfitting)のリスク
過学習とは、モデルが学習データに過剰に適合してしまい、そのデータに対しては高い正解率を示すものの、未知の新しいデータに対してはうまく対応できなくなる現象です。これは、学習データの量が少なすぎたり、内容が偏っていたりする場合に発生しやすくなります。
例えば、特定の言い回しの質問にしか答えられない、非常に応用力の低いAIになってしまう可能性があります。これを避けるためには、学習データだけでなく、モデルの性能を客観的に評価するための検証用データを別途用意し、汎化性能(未知のデータへの対応能力)を常にチェックしながら調整を進める必要があります。
元のモデルが持つバイアスの継承
ファインチューニングのベースとなる大規模言語モデルは、インターネット上の膨大なテキストデータを学習しています。そのため、そのデータに含まれる社会的偏見や差別的な表現といったバイアスを、意図せず学習してしまっている可能性があります。
ファインチューニングを行っても、これらの根本的なバイアスが消えるわけではなく、むしろ特定の文脈で増幅されてしまうリスクも存在します。生成AIを企業活動で利用する上では、こうした倫理的な側面にも配慮が必要です。不適切な出力をしないようにフィルタリングの仕組みを設けたり、定期的に出力内容を監査したりするなどの対策が求められます。
https://a-x.inc/blog/ai-development
ファインチューニングが不要・不向きなケースとは?
ファインチューニングは万能ではなく、特定の状況では不要、あるいは不向きな場合があります。特に、高性能な基盤モデルの登場により、より手軽な手法で目的を達成できるケースが増えています。
例えば、OpenAIのGPT-5.6シリーズやGoogleのGemini 3.5ファミリーなどの最新モデルは、汎用的なタスクで非常に高い性能を発揮します。しかし、特定の専門領域や業務タスクで、そのまま十分な精度が出るとは限りません。
そのため、まずはプロンプトエンジニアリングで目的の応答品質が得られるか、小規模な検証(PoC)で確認することが推奨されます。このアプローチで十分な結果が得られるなら、コストのかかるファインチューニングは不要です。
また、社内文書やマニュアルなど、特定の知識に基づいた回答を生成させたい場合も、RAG(Retrieval-Augmented Generation)が有効な選択肢です。 RAGは、AIが外部の知識データベースを参照しながら回答を生成する技術です。 この方法は、学習データ準備のコストをかけずに専門性を高められる利点があります。 情報が頻繁に更新される製品サポートや、社内規定に関する問い合わせ対応などにも適しています。
そもそも、ファインチューニングの品質を左右する高品質な学習データを大量に用意できない場合も、この手法は不向きです。 かけたコストに見合う効果が期待できない場合も同様です。自社の課題とリソースを考慮し、他の手法と比較検討した上で最適な手法を選択することが重要になります。
【事例別】生成AIファインチューニングの具体的な活用シーン
ファインチューニングはデータ準備や運用にコストがかかりますが、汎用的な大規模言語モデルでは解決できない特定の課題に対して、費用対効果の高い解決策となります。特に、独自の専門知識や特定のスタイルが求められる業務でその真価を発揮します。生成AIのファインチューニングは、汎用モデルでは対応が難しい、より専門的でクローズドな領域で有効な技術です。
具体的な活用シーンは、主に以下の3つのようなケースが挙げられます。
- 専門分野に特化した応答精度の向上
法律や医療など、業界固有の専門用語や知識体系が求められる問い合わせに対応するチャットボットを構築できます。 社内の文書や過去の対応履歴を学習させることで、一般的なモデルでは難しい、文脈を深く理解した高精度な回答が可能になります。 - 特定の文体・トーンの再現
企業のブランドイメージに沿った一貫性のあるマーケティングコピーやプレスリリースを自動生成できます。過去の文章を学習させることで、特定の人物やキャラクターが持つ独特の口調やスタイルを再現した対話シナリオの作成も可能です。 - 業界独自の文章分類や要約
金融レポートや医療カルテ、技術論文といった長文の専門文書から、必要な情報を正確に抽出し、分類や要約を自動化するタスクで有効です。 これにより、専門家が膨大な資料を確認する時間を大幅に削減できます。
こうしたファインチューニングの基盤には、高性能なモデルが活用されます。例えば、2026年6月に発表されたOpenAIの「GPT-5.6」シリーズや、Google I/O 2026で公開された「Gemini 3.5」ファミリーなどが代表的です。GoogleのVertex AIでは、Gemini 3.5 Flashなどのモデルに対し、特定のタスクに合わせて調整する教師ありファインチューニングが提供されています。 このように、最新モデルをファインチューニングすることは、自社独自の価値を生み出すための強力な手段と言えるでしょう。
ファインチューニングの実践手順5ステップ
生成AIのファインチューニングは、思い付きで始められるものではなく、体系的なアプローチが成功の鍵を握ります。自社の目的に特化したAIを構築するためには、「目的の明確化」から「評価と展開」まで、大きく分けて5つのステップで計画的に進めるのが一般的です。
現在、主要なクラウドプラットフォームがファインチューニングのためのサービスを提供しています。例えば、Google Cloud (Vertex AI) や Amazon Web Services (Amazon Bedrock) では、比較的容易にモデルをカスタマイズできます。
一方で、OpenAIの動向には注意が必要です。同社はカスタムモデルプログラムへの移行に伴い、従来のセルフサービスによるファインチューニング機能を段階的に終了すると発表しました。 2026年5月以降、新規ユーザーはアクセスできなくなり、既存ユーザーも2027年1月6日をもって新たな学習ジョブを作成できなくなります。 利用を検討する際は、必ずOpenAIの公式ドキュメントで最新の提供状況を確認してください。
各ステップを着実に実行することで、リスクを最小限に抑え、投資対効果の高い自社専用AIを構築できます。この流れに沿ってプロジェクトを計画することで、手戻りを防ぎ、効率的に開発を進められます。
ステップ1:目的の明確化とベースモデルの選定
最初に、「ファインチューニングによって何を達成したいのか」という目的を具体的に定義します。例えば、「顧客からの技術的な問い合わせに、社内ナレッジベースを元に自動応答させたい」「ブランドイメージに沿ったSNS投稿文を自動生成したい」など、解決したい課題を明確にします。
目的が定まったら、そのタスクに最も適したベースモデルを選定します。対話性能を重視するならOpenAIのGPTシリーズやAnthropicのClaudeシリーズ、オープンソースで自由にカスタマイズしたいならMetaのLlama 3など、各モデルの特性を比較検討します。この段階で、目的とモデルのミスマッチがないか慎重に判断することが重要です。
ステップ2:高品質な学習データセットの準備
次に、プロジェクトの成否を左右する最も重要な工程である、学習データセットの準備に取り掛かります。ステップ1で定義した目的に沿って、「指示(prompt)」と「理想的な出力(completion)」のペア形式でデータを大量に作成します。
例えば、問い合わせ応答AIであれば、想定される質問と模範解答のペアを用意します。データの品質がモデルの性能に直結するため、内容の正確性、一貫性、多様性を確保することが求められます。社内の専門家や担当者が協力し、質の高いデータセットを地道に構築していく必要があります。
ステップ3:学習環境の構築と設定
データセットの準備ができたら、モデルを学習させるための環境を構築します。Google Cloud (Vertex AI) や Amazon Web Services (Amazon Bedrock) など、主要なクラウドプラットフォームがファインチューニングのためのサービスを提供しています。(出典:生成AIのファインチューニング完全ガイド|ビジネス活用のためのステップと事例)
以前はOpenAIも有力な選択肢でしたが、Fine-Tuning APIの仕様が変更されています。 利用を検討する際は、OpenAIの公式発表(2026年5月)で最新の提供状況を必ず確認してください。 現在では、前述の主要クラウドのほか、CohereやMistral AIなども目的に応じた選択肢となります。
これらのサービスを利用すれば、自前で高価なGPUサーバーを用意することなく、必要な時に必要なだけ計算リソースを借りられます。管理画面やAPIを通じて学習データをアップロードし、ベースモデルを選択します。例えば、GoogleのGemini 3.5 ProやOpenAIのGPT-5.5 Proなどが選択肢になります。 その後、学習の進め方を制御するハイパーパラメータを設定します。
ステップ4:モデルのトレーニングとハイパーパラメータ調整
環境設定が完了したら、いよいよモデルのトレーニングを開始します。アップロードしたデータセットを用いて、ベースモデルの追加学習を実行します。この際、「ハイパーパラメータ」と呼ばれる、学習の進め方を制御するための数値を調整することが重要です。(出典:スタンフォード大学 CS 230 チートシート)
ハイパーパラメータには、学習の速度を調整する「学習率」や、データセットを何回繰り返し学習させるかを示す「エポック数」などがあります。これらの値を適切に設定することで、過学習を防ぎ、モデルの性能を最大限に引き出すことができます。最初はプラットフォームの推奨値で試し、結果を見ながら微調整していくのが一般的です。
ステップ5:性能評価とデプロイ
モデルのトレーニングが完了したら、その性能を客観的に評価します。事前に用意しておいた「検証用データセット」(学習には使っていない未知のデータ)を入力し、出力の質や正解率を確認します。学習前のベースモデルと比較して、性能がどの程度向上したかを定量的に評価することが重要です。
性能が目標水準に達していることが確認できたら、モデルを実運用環境に展開(デプロイ)します。これにより、API経由でアプリケーションや社内システムからファインチューニング済みモデルを呼び出し、実際の業務で利用できるようになります。デプロイ後も、ユーザーからのフィードバックを収集し、継続的にモデルを改善していくサイクルを回すことが理想的です。
https://a-x.inc/blog/ai-model
ファインチューニングに必要なデータとコスト

ファインチューニングのコストは、主に「データ準備の人件費」と「計算リソースの利用料」で構成されます。 タスクの専門性に応じて数百件以上の高品質なデータが必要で、その準備費用が全体の半分以上を占めることもあります。
計算リソースの利用料は、「トレーニング料金」と「モデル利用料(推論料金)」に分かれます。 具体的な費用は、OpenAIのGPT-5.6シリーズやGoogleのGemini 3.5ファミリーなど、利用するAIモデルやプラットフォームによって大きく変動するため、事前に全体像を把握しておくことが重要です。
- データ準備コスト(人件費):収集したデータに理想的な回答を付与(アノテーション)したり、形式を整えたりする作業費用です。AIの性能を直接左右するため、最も重要視すべきコストと言えます。
- トレーニング料金:準備したデータでAIモデルを追加学習させる際に、一度だけ発生する費用です。一般的に、学習データのトークン数や学習時間に応じて課金されます。
- モデル利用料(推論料金):ファインチューニングした専用モデルをAPI経由で利用する際にかかる費用です。多くの場合、入力と出力のトークン数に応じた従量課金制が採用されています。
例えば、OpenAIの公式料金ページで示されているように、ファインチューニング済みモデルの利用料は、ベースモデルよりも高価に設定される傾向があります。2026年6月に発表されたGPT-5.6シリーズでは、複数の価格帯のモデルが提供されるなど、料金体系は頻繁に改定されるため注意が必要です。
そのため、最新の正確な料金やサービス提供状況は、必ず公式サイトで確認するようにしてください。各プラットフォームの料金ページで、詳細な見積もりを取得することをおすすめします。
(出典:LLMファインチューニング)
必要なデータセットの種類と量
ファインチューニングで最も一般的に使用されるのは、「指示チューニング(Instruction Tuning)」用のデータセットです。これは、「ユーザーからの指示(Instruction/Prompt)」と「AIが返すべき理想的な応答(Output/Completion)」をペアにした形式のデータです。
必要なデータ量に明確な必要データ量の定義はありませんが、一般的にはタスクの難易度やモデルの規模に応じて 数百〜数千以上 の質の高い「指示(プロンプト)と理想的回答」のペアデータが用意されることが多いです。(出典:生成AIのファインチューニングとは?)
データの前処理とアノテーションの重要性
収集したデータをそのまま学習に使えるケースは稀で、通常は「前処理」という作業が必要です。前処理には、表記ゆれの統一、個人情報などの不要な情報の削除、データを特定のフォーマット(JSONL形式など)に変換する作業が含まれます。
また、データに理想的な応答を付与する「アノテーション」は、ファインチューニングの品質を決定づける極めて重要なプロセスです。この工程には専門的な知識が必要な場合も多く、人件費という形でプロジェクトのコストに大きく影響します。データ準備のコストが、プロジェクト全体の半分以上を占めることも珍しくありません。
主要プラットフォーム別の料金体系比較(2026年時点)
ファインチューニングの実行コストは、利用するクラウドプラットフォームによって大きく異なります。多くは、学習時に処理した「トークン数(単語や文字のような単位)」や、計算リソースの利用時間に基づいて課金されます。
主要なプラットフォームでは、それぞれ特徴の異なる料金体系を提供しています。
プラットフォーム 料金モデル 特徴
・チューニング済みモデル利用時の入出力トークン数
・デプロイ後の推論(ベースモデルと同料金)
・モデルストレージ料金(月額)
・推論コスト(プロビジョンドスループットまたはオンデマンド)
※上記は2026年7月時点の一般的な料金モデルです。最新の正確な料金や提供モデルは、各サービスの公式サイトで必ずご確認ください。
例えばOpenAIでは、ファインチューニングの料金は利用するモデルや学習データの量によって大きく変動します。ベースとなるモデルのAPI利用料金に加え、学習処理で消費したトークン数に応じたトレーニング費用が発生する仕組みです。2026年7月時点では最新モデル「GPT-5.6」シリーズが限定提供されており、料金体系も変更される可能性があるため、プロジェクト開始前には公式サイトの料金ページなどで試算することが不可欠です。(出典:OpenAI Pricing, GPT-5.6発表)
コストを抑えるためのポイント
ファインチューニングのコストを抑えるには、LoRA(Low-Rank Adaptation)に代表される「PEFT(Parameter-Efficient Fine-Tuning)」という軽量化技術の活用が極めて効果的です。
PEFTは、大規模言語モデル(LLM)が持つ膨大なパラメータの全てを更新するのではなく、新たに追加したごく一部のパラメータのみを学習対象とします。このアプローチの代表例が、Edward J. Huらが2021年に発表した論文「LoRA: Low-Rank Adaptation of Large Language Models」で提案されたLoRAです。これにより、学習に必要な計算リソースと時間を大幅に削減し、コストを数分の一から数十分の一に抑えることが可能です。
例えば、全てのパラメータを更新するフルファインチューニングでは、高性能なGPUを複数台、長時間確保する必要があります。しかし、PEFTを用いることで、一般的な性能の単一GPUでも数時間で学習が完了するケースも少なくありません。結果として、クラウドサービスの利用料金を大幅に圧縮できます。
さらに、学習対象のパラメータが少ないため、チューニング後のモデル(追加パラメータ部分)の保存に必要なストレージ容量が数GBから数十MB程度に削減できる利点もあります。また、比較的少量の学習データでも性能を発揮しやすいため、データ収集やアノテーション(教師データ作成)にかかるコストと時間の削減にも繋がります。
【費用シミュレーション】ファインチューニングのコスト内訳
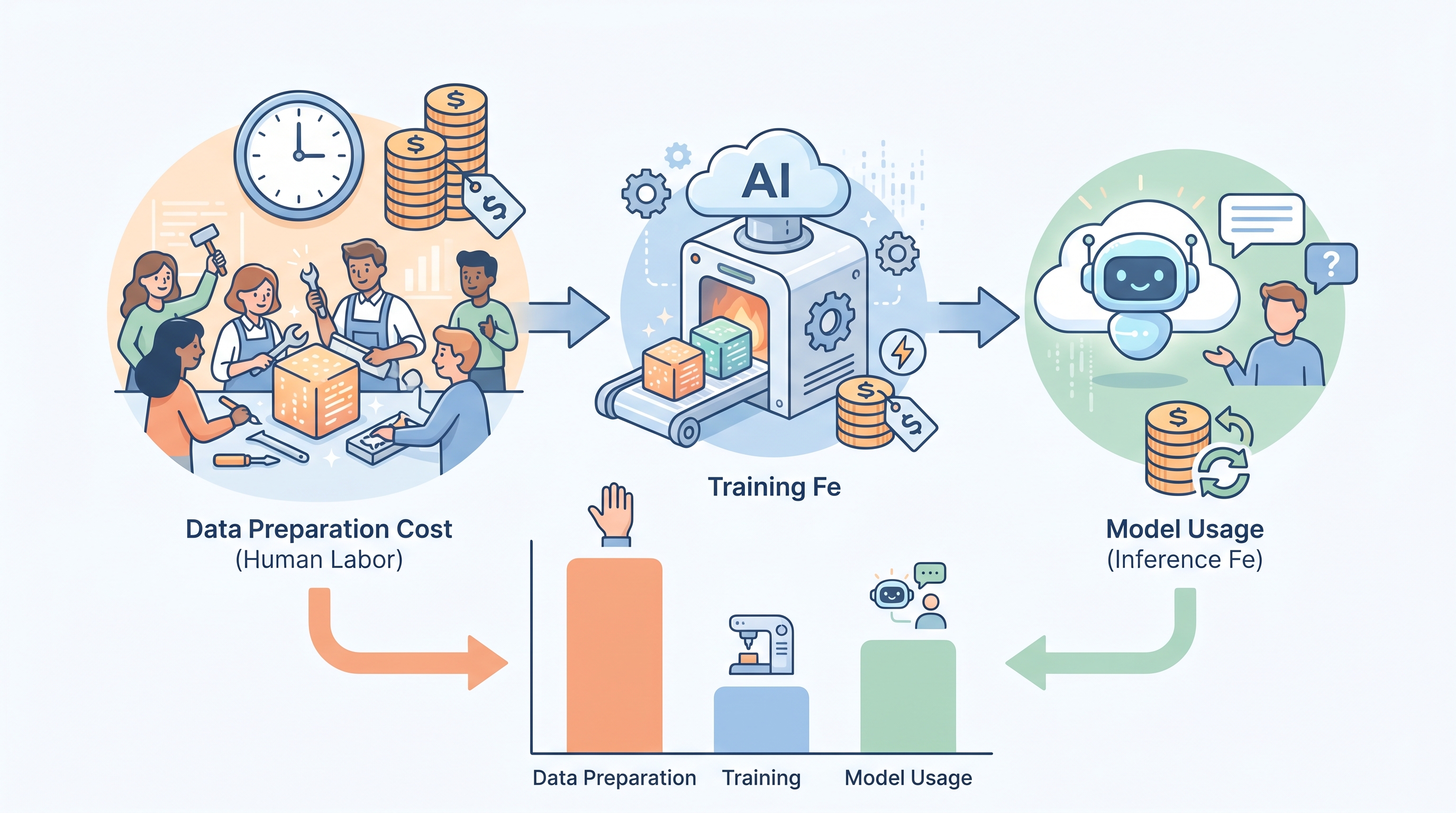
ここでは具体的な費用感を掴むため、顧客からの問い合わせに自動応答するAIを開発するケースで、ファインチューニングのコスト内訳をシミュレーションします。OpenAIが2026年6月に発表したGPT-5.6シリーズの中価格帯モデル「Terra」を使い、500件の高品質なQ&Aデータセット(1件あたり平均1,000トークン)を用意する前提で計算します。
本シミュレーションで用いる料金や単価はすべて仮定の数値です。GPT-5.6シリーズの価格は限定プレビュー段階のため、実際の料金はOpenAI公式サイトで必ず確認してください。
- データ準備コスト(人件費):1件のデータ作成・整形に20分(時給1,800円換算で600円)かかると仮定します。この場合、「500件 × 600円 = 300,000円」の人件費が発生します。AIの性能を左右する最も重要な投資であり、実際の作業時間や単価で費用は変動します。
- トレーニング料金:総トークン数は50万(500件 × 1,000トークン)です。料金を既存モデル(例: GPT-4o)の100万トークンあたり25ドルと仮定します。1ドル162.5円(2026年7月9日時点の為替レート)で換算すると、費用は約2,031円です。
- モデル利用料(推論料金):ファインチューニング済みモデルのAPI利用料は、ベースモデルより高くなる傾向があります。例えば、Terraのベースモデルの入力料金が100万トークンあたり2.5ドルでも、チューニング後は3.75ドル(1.5倍)になる、といった料金設定が考えられます。
このシミュレーションから、ファインチューニングの初期費用の大半をデータ準備コストが占めることがわかります。トレーニング料金自体は比較的手頃な場合も多いですが、AIの品質を決定づけるデータへの投資を軽視しないことが、プロジェクト成功の鍵を握ります。
(出典:A preview of GPT-5.6 Sol Terra and Luna)
【2026年】ファインチューニングが可能な主要生成AIモデル7選

ファインチューニング可能な生成AIモデルは、自社の目的、予算、技術力に応じて最適な選択肢を選ぶことが成功の鍵です。API経由で手軽に利用できる商用モデルから、自由にカスタマイズできるオープンソースモデルまで、選択肢は豊富に存在します。
2026年7月現在、主要なAI開発企業がモデルのファインチューニング機能を拡充しています。例えばOpenAIは、2026年6月26日にGPT-5.6シリーズを発表し、7月9日から一般公開を開始しました。 また、Googleも開発者会議「Google I/O 2026」でGemini 3.5ファミリーを発表し、同様の環境を整備しています。
一方で、オープンソース分野ではMeta社のLlama 3シリーズが広く活用されています。Llama 3.1などのモデルは、特定の業務領域に深く特化したモデルを自社で構築したい場合に有力な選択肢です。 ここでは、これらの最新動向を踏まえ、代表的な生成AIモデルを7つ紹介します。
(出典:Vertex AI: model versions)
(出典:AI tech trends: fine-tuning business guide)
1. OpenAI (GPTシリーズ)
ChatGPTで知られるOpenAIは、同社のGPT-5.6をはじめとする高性能モデルで利用できるファインチューニング機能を提供しています。これにより、独自のデータセットを用いて、特定のタスクに特化したカスタムモデルを効率的に作成できます。
中でも、2026年6月26日に発表されたGPT-5.6シリーズ(Sol/Terra/Luna)は、コーディング、PC操作、データ分析といった実務能力が大幅に強化されました。特に、複雑な指示を理解し、複数のツールを横断して自律的にタスクを実行する能力が向上しています。
OpenAIのプラットフォームは長年の実績と豊富なドキュメントがあり、開発者コミュニティも活発なため情報収集が容易です。ただし、一部の旧式ファインチューニングAPIは段階的な提供終了が発表された点には注意が必要です。
この発表によると、新規ユーザーは利用できず、既存ユーザーも新たなモデルのトレーニングは2027年1月6日までとされています。最新の対応状況は変動するため、公式ガイドで必ず確認してください。
例えば、特定の対話スタイルを学習させたり、専門的な業界用語や複雑な指示への追従能力を高めたりしたい場合に、OpenAIのモデルは有力な選択肢です。これにより、汎用モデルでは対応が難しい独自のタスクにも、高い精度で応答するAIを構築できます。
2. Google (Geminiシリーズ)
Googleは、統合AI基盤であるVertex AI上で、最新モデルのチューニング機能を提供しています。特に、2026年4月のGoogle Cloud Next ’26で発表された「Gemini Enterprise Agent Platform」は、AIエージェントの構築からガバナンス、最適化までを一元管理できる企業向け開発・運用基盤です。
チューニングには、2026年5月のGoogle I/Oで発表された軽量・高速なGemini 3.5 Flashや、2026年2月19日にリリースされ複雑な問題解決を得意とするGemini 3.1 Proなどのモデルを利用できます。 これにより、コストと性能のバランスを取りながら、目的に応じた最適なモデルを選択してカスタマイズが可能です。
さらに、このプラットフォームはBigQueryやCloud StorageといったGoogle Cloudの多様なサービスとシームレスに連携します。 企業が保有する構造化データやドキュメントなどを活用し、本格的なAIエージェント開発が可能です。単にモデルをカスタマイズするだけでなく、自律的にタスクを実行する高度なAIエージェントを構築・管理したい場合に最適です。
(出典:Gemini 3.1 Pro documentation)
3. Anthropic (Claudeシリーズ)
高い対話性能と安全性で評価されるAnthropic社のClaudeシリーズも、特定の用途に合わせてモデルをカスタマイズできます。モデルや提供形態により、利用できるカスタマイズの方法が異なるため、事前の確認が重要です。
Anthropicは、2026年のGoogle Cloud Next ’26での発表にもあるように、Amazon BedrockやGoogle Cloud Vertex AIといった主要なクラウドプラットフォームと協業しています。これらの基盤を通じて、パートナー経由でのモデルカスタマイズや、管理されたチューニング機能を提供しています。
例えば、Amazon BedrockではClaude 3 Haikuでセルフサービスによるファインチューニングが可能です。AWSの発表「Fine-Tuning for Anthropic’s Claude 3 Haiku Model in Amazon Bedrock Is Now Generally Available」(2024年)で一般提供が開始され、ユーザーは自身のデータを使ってモデルを調整できます。 一方で、より高性能なClaude Opus 4.7や最新のClaude Haiku 4.5、特定の安全要件を満たすために再展開されたClaude Fable 5などを利用する際は、対応状況の確認やパートナーへの申請、追加契約が必要な場合があります。
利用を検討する際は、Amazon BedrockやGoogle Cloud Vertex AIの公式ドキュメントで、対象モデルの最新の対応状況を確認してください。特に、長文の読解や生成、そして倫理性を重視するアプリケーション開発で強みを発揮します。
4. Mistral AI (Mistral Large, Mixtral)
フランスのスタートアップであるMistral AIは、高性能なオープンソースモデルと商用モデルの両方を提供しています。特にオープンソースのMixtralモデルは、比較的少ない計算コストで高い性能を発揮することから人気を集めています。オープンソースであるため、モデルの内部構造まで踏み込んだ自由なカスタマイズが可能です。技術力のある企業が、コストを抑えつつ独自のAIを構築したい場合に有力な選択肢です。
5. Cohere (Command R+)
Cohereは、特にエンタープライズ向けのAI開発に強みを持つ企業です。同社のCommand R+モデルは、ビジネスユースケースに特化した機能が豊富で、RAG(検索拡張生成)との連携も考慮されています。信頼性やデータセキュリティを重視する企業の基幹システムに組み込むAIとして、高い評価を得ています。多言語対応能力も高く、グローバルに展開するビジネスにも適しています。
6. Meta (Llama 3)
Metaが開発したLlama 3は、現在最も人気のあるオープンソース大規模言語モデルの一つです。 その性能は多くのベンチマークで他のオープンモデルを上回り、一部のクローズドモデルに匹敵すると評価されています。
Llama 3をファインチューニングの基盤として選ぶことには、主に3つのメリットがあります。
- 緩やかなライセンスと商用利用: 月間アクティブユーザー数が7億人未満であれば追加ライセンスなしで商用利用が可能です。 これにより、多くの開発者や企業が自社サービスに組み込みやすくなっています。
- 高い性能とカスタマイズ性: モデルのアーキテクチャや重みが公開されているため、内部構造にアクセスして独自のデータセットでファインチューニングできます。 これにより、特定の業務ドメインに特化した高精度なモデルを構築できます。
- 活発な開発者コミュニティ: Hugging Faceなどのプラットフォームを中心に巨大なエコシステムが形成されています。 世界中の開発者によって、ファインチューニングを効率化するツールや知見が日々共有されており、開発コストの抑制につながります。
これらの理由から、コストを抑えつつ最先端の性能を持つ独自のAIモデルを開発したい場合に、Llama 3は最も有力な選択肢の一つと言えるでしょう。
7. 日本語特化のオープンソースモデル
海外製のモデルだけでなく、日本の文化や言語ニュアンスに特化した日本語LLMも登場しています。NTTが開発する「tsuzumi」や、rinna社、Stability AI Japanなどが開発するモデルは、日本語の処理能力で海外製モデルを上回る性能を示すことがあります。 実際にNTTは2026年5月19日、tsuzumiが図表を含む日本語ビジネス文書の読解能力を強化したと発表しました。
これらの多くはオープンソースとして公開されており、日本のビジネス環境に最適化されたAIを構築する上で価値のある選択肢です。また、世界的に利用されるLlama 3などを基盤に、日本語性能を強化したモデル開発も進んでいます。 実際に、ELYZAや東京工業大学などの国内組織がLlama 3を基盤とし、日本語性能を独自に高めたモデルを公開する事例も増えています。
一方で、次世代モデルに関する最新情報の扱いには注意が必要です。例えば、OpenAIの「GPT-5.6」シリーズは2026年6月下旬に3つのモデル(Sol/Terra/Luna)が発表され、当初は限定的な提供でした。 しかし、2026年7月上旬には一般公開が予定されており、状況は常に変化します。 技術選定の際は、信頼できる情報源から最新のリリース状況を確認することが不可欠です。(出典:【2024年最新】日本語LLM(大規模言語モデル)とは?)
https://a-x.inc/blog/ai-use-case
(出典:【2024年最新】日本語LLM(大規模言語モデル)とは?)
専門知識がなくても大丈夫!AX CAMPのAI活用支援
「ファインチューニングは有効そうだが、自社での実践は技術的に難しい」「何から手をつければ良いのかわからない」と感じる方も多いのではないでしょうか。生成AIの高度な活用には専門知識も必要ですが、適切なパートナーがいれば、着実に成果へ繋げられます。
株式会社AXが提供する「AX CAMP」は、AI活用の企画から導入、研修、定着までを一貫して支援するサービスです。非エンジニアでもAIを実務に落とし込み、業務を改善できる体制の構築をゴールとしています。個別の成果保証に関する条件や具体的な提供範囲は、公式サイトにてご確認ください。
AX CAMPは、企業の状況に合わせて以下の4領域で支援を提供します(2026年5月現在)。
- オーダーメイド研修:貴社の業務内容と課題をヒアリングし、明日から使える具体的なAI活用術に絞ったカリキュラムを設計します。
- 伴走・導入支援:アイデアの壁打ちから、ファインチューニングのような高度なツールの実装まで、専門家が二人三脚でサポートします。実際に、医療分野ではAI活用により退院時サマリーの作成時間を3分の1に削減したという学術報告もあります。
- 活用定着サポート:研修後もチャットでいつでも専門家に質問できる環境を用意し、現場でのAI活用を習慣化させます。
- 実績に基づくノウハウ:業種や規模を問わず、多くの企業で業務効率化や生産性向上を実現してきました。例えば、月75時間の広告運用業務を自動化したり、24時間かかっていた記事執筆を10秒に短縮したりといった成果が生まれています。
高度な技術導入の検討はもちろん、「まずはAIで何ができるか知りたい」「小さな業務改善から始めたい」といったご相談も歓迎です。専門家が貴社の状況を伺い、最適なAI活用の第一歩をご提案します。詳しいサービス内容や導入事例は、下記の資料でご紹介しています。


法人向けAI研修
AX CAMP 無料資料
(出典:AX CAMP – AI活用支援)
生成AIのファインチューニングに関するよくある質問(FAQ)
1. 生成AIのファインチューニングとは何ですか?RAGとの違いも教えてください。
ファインチューニングは、学習済みAIモデルに独自のデータを追加学習させ、特定のタスクに特化させる手法です。 モデル自体を「再教育」するイメージです。一方、RAGは外部のデータベースから最新情報などを検索し、それを基に回答を生成する技術で、モデルに「カンニング」させる手法と言えます。 モデルの知識を更新するのがファインチューニング、外部知識を参照するのがRAGという点が大きな違いです。
2. ファインチューニングは、どのような業界や業務で活用できますか?
ファインチューニングは、専門知識が求められる業界や、定型業務を自動化したい場面で特に有効です。例えば、2026年5月に発表されたGoogleのGemini 3.5ファミリーのような最新AIモデルを自社データで追加学習させることで、業界特有の課題解決を加速できます。
具体的な活用例は多岐にわたります。
- 金融業界:専門用語や金融商品を学習させ、顧客からの問い合わせに高精度で回答するAIチャットボットを開発します。 市場分析レポートや融資稟議書の自動生成にも応用できます。
- 医療分野:最新の医学論文や臨床データを学習させることで、診断支援AIや治療計画の提案システムを構築します。 実際に、退院時サマリーの作成時間を3分の1に削減した事例も報告されています。
- 法務・コンプライアンス:膨大な契約書や過去の判例データを学習させ、契約書レビューの自動化やリスク箇所の特定を高速化します。
- マーケティング・製造:特定のブランドボイスや製品情報を学習し、ターゲット顧客に響く広告コピーやSNS投稿を自動生成します。 実際にバナー制作を自動化し、投資収益率(ROI)を1.4倍に向上させた事例もあります。
このように、各業界の固有な言語や文脈、非公開データをAIに学習させることで、汎用モデルでは難しい特化したタスクの自動化と業務効率化を実現します。実際に、Google Cloudが提供するVertex AIのようなプラットフォームでは、企業が持つデータを使って安全にモデルをカスタマイズする環境が整備されています。 (Google I/O ’26でのAIと機械学習のイノベーションで詳細が報告されています)。
(出典: Innovations from Google I/O 26 on Google Cloud)
3. 生成AIのファインチューニングには、どれくらいの費用がかかりますか?
ファインチューニングの費用は、利用するAIモデルの種類、学習データの量、計算リソース(GPU)の規模によって大きく変動します。そのため、目的と要件に応じた適切な予算計画が重要です。
具体的な費用感として、小規模なPoC(概念実証)であれば100万円から500万円程度で着手できる場合があります。 中規模で実用的なシステムを開発する場合は500万〜1,500万円、さらに独自モデルの構築を目指す大規模な開発では3,000万円以上が必要になることも珍しくありません。 (出典:AINOW 2026年4月23日)
主なコストの内訳は、以下の4つの要素で構成されます。
- データ関連費用:AIの学習に不可欠なデータの収集、クレンジング、ラベル付け(アノテーション)にかかる作業コストです。
- 計算リソース費用:高性能なGPUサーバーの利用料や、クラウドプラットフォームのサービス料金です。学習時間やモデルの規模に応じて変動します。
- エンジニア人件費:AIモデルの設計、学習、評価を担う専門人材の費用で、総コストの大部分を占めることが多いです。
- 運用・保守費用:モデルを導入した後も、性能を維持・向上させるための継続的なチューニングや監視にかかるコストです。
費用を抑えながら成果を出すには、まず小規模なデータセットでPoCから始めるスモールスタートが有効です。また、オープンソースで公開されている事前学習済みモデルを基盤にしたり、LoRAのような効率的なチューニング手法を採用したりすることで、計算リソースを節約できます。 OpenAIやGoogleなどが提供するAPIを活用する場合、トレーニングと運用(推論)で料金が分かれているため、事前に公式サイトで料金体系を確認することが重要です。
まとめ:ファインチューニングで自社専用の生成AIを構築しよう
この記事では、生成AIのファインチューニングについて、その基本概念からRAGとの違い、メリット・デメリット、実践手順、そして企業での活用事例までを網羅的に解説しました。改めて、本記事の重要なポイントを振り返ります。
- ファインチューニングは、既存のAIモデルを自社データで追加学習させ、特定のタスクに特化させる技術です。
- RAGは外部知識を都度参照する手法であり、知識の更新頻度が高いタスクに向いています。両者を組み合わせることも有効です。
- メリットは、専門タスクの精度向上やプロンプトの簡略化ですが、デメリットとして高品質なデータの準備と計算コストがかかります。
- 実践には、目的設定からデータ準備、学習、評価まで体系的な5つのステップを踏むことが成功の鍵となります。
- OpenAIのGPTシリーズやMetaのLlama 3など、多くの主要モデルがファインチューニングに対応しており、選択肢は豊富です。
ファインチューニングを使いこなすことで、汎用的なAIツールを導入するだけでは得られない、自社独自の競争力を持ったAIソリューションを構築できます。顧客対応の品質向上、マーケティングコンテンツの自動生成、専門的な社内文書の検索効率化など、その応用範囲は無限大です。
もし、自社だけでのAI導入やファインチューニングの実践に不安を感じる場合は、専門家のサポートを受けることをお勧めします。弊社「AX CAMP」では、貴社のビジネス課題に合わせた最適なAI活用のロードマップ作成から、実践的なスキル習得、そして導入後の定着までをワンストップでご支援します。まずは無料相談で、貴社の課題をお聞かせください。

法人向けAI研修
AX CAMP 無料資料